


If you have spent any time evaluating AI tools, you know that marketing claims and real-world performance rarely line up.
Most AI translation benchmarks test short or sanitized sentences rather than the kinds of documents businesses actually translate every day: legal contracts, technical manuals, multilingual product descriptions, customer support scripts, and compliance-heavy documentation.
To better understand how modern AI translation systems behave under real-world conditions, we compared outputs from 22 AI translation engines across multiple document categories and language pairs.
The findings revealed an important pattern: fluency is no longer the main challenge in AI translation. Reliability and consistency are.
The Problem With How Most People Evaluate AI Translation
According to the 2026 AI Translation Accuracy Benchmark, AI translation now achieves 96% accuracy across 133 languages. That sounds compelling until you dig into what that remaining 4% actually contains: mistranslated contract clauses, reversed safety warnings, and incorrect medical dosages. The errors that look like rounding noise are, in practice, the errors that cost organizations the most.
The problem is not accuracy in the aggregate. The problem is which errors each model makes, and whether those errors are predictable. A tool that scores 94% on a benchmark but consistently fails on legal negotiations is not a 94% tool for legal teams. It is a liability. Yet most side-by-side reviews treat models as interchangeable at similar performance tiers.
This is the same challenge Fileion readers face when comparing any category of software: headline specs do not reveal what matters in practice. Just as comparing remote desktop tools side by side reveals performance gaps invisible in feature lists, testing AI translation under real conditions uncovers differences that no leaderboard captures.
How the Test Was Structured
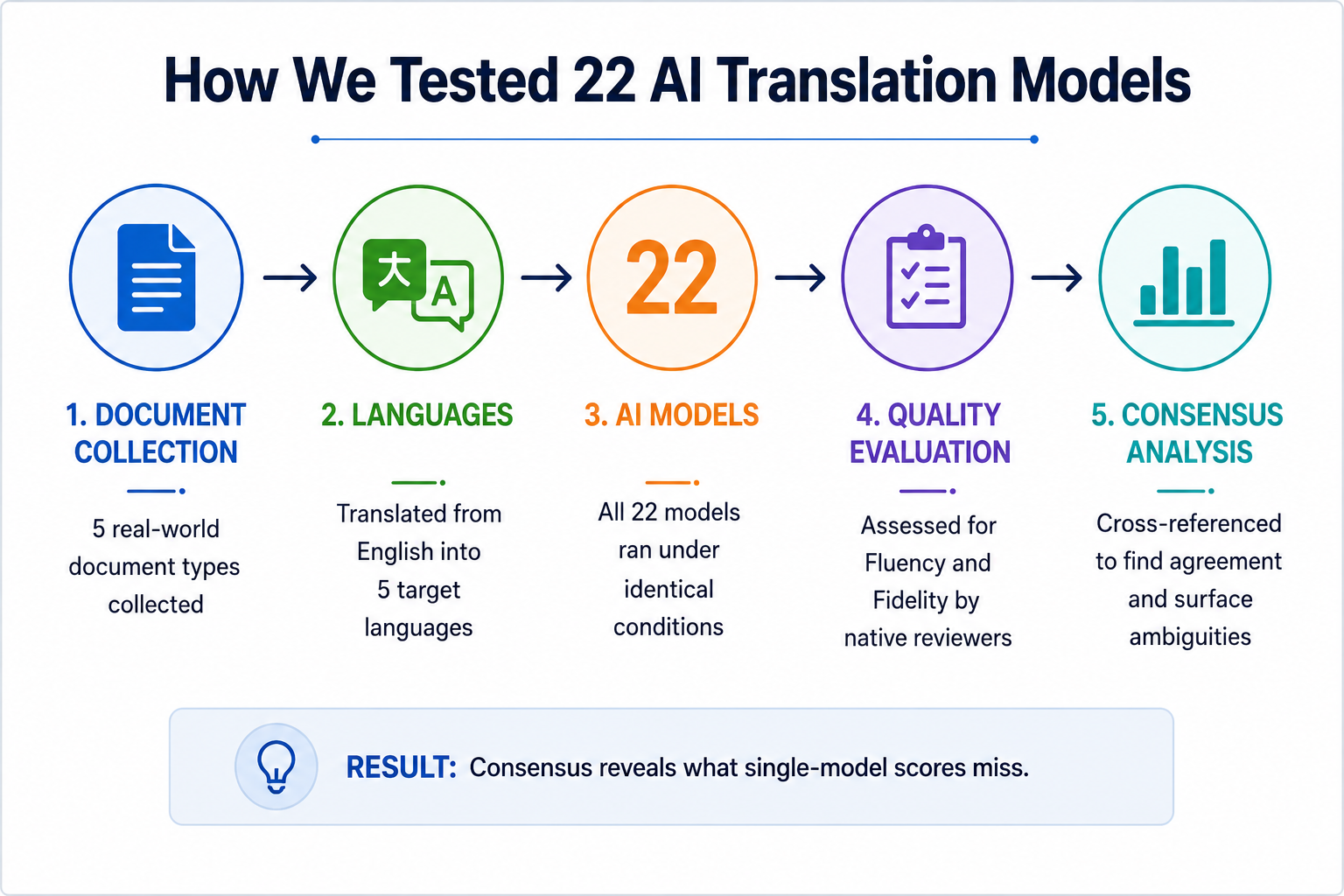
Document Categories Tested
The evaluation included five document categories:
|
Document Type |
Evaluation Focus |
|
Legal Contracts |
Clause fidelity, negation handling |
|
Technical Specifications |
Terminology consistency |
|
Marketing Copy |
Tone and localization |
|
Academic Abstracts |
Semantic precision |
|
Customer Support Scripts |
Conversational clarity |
Target Languages
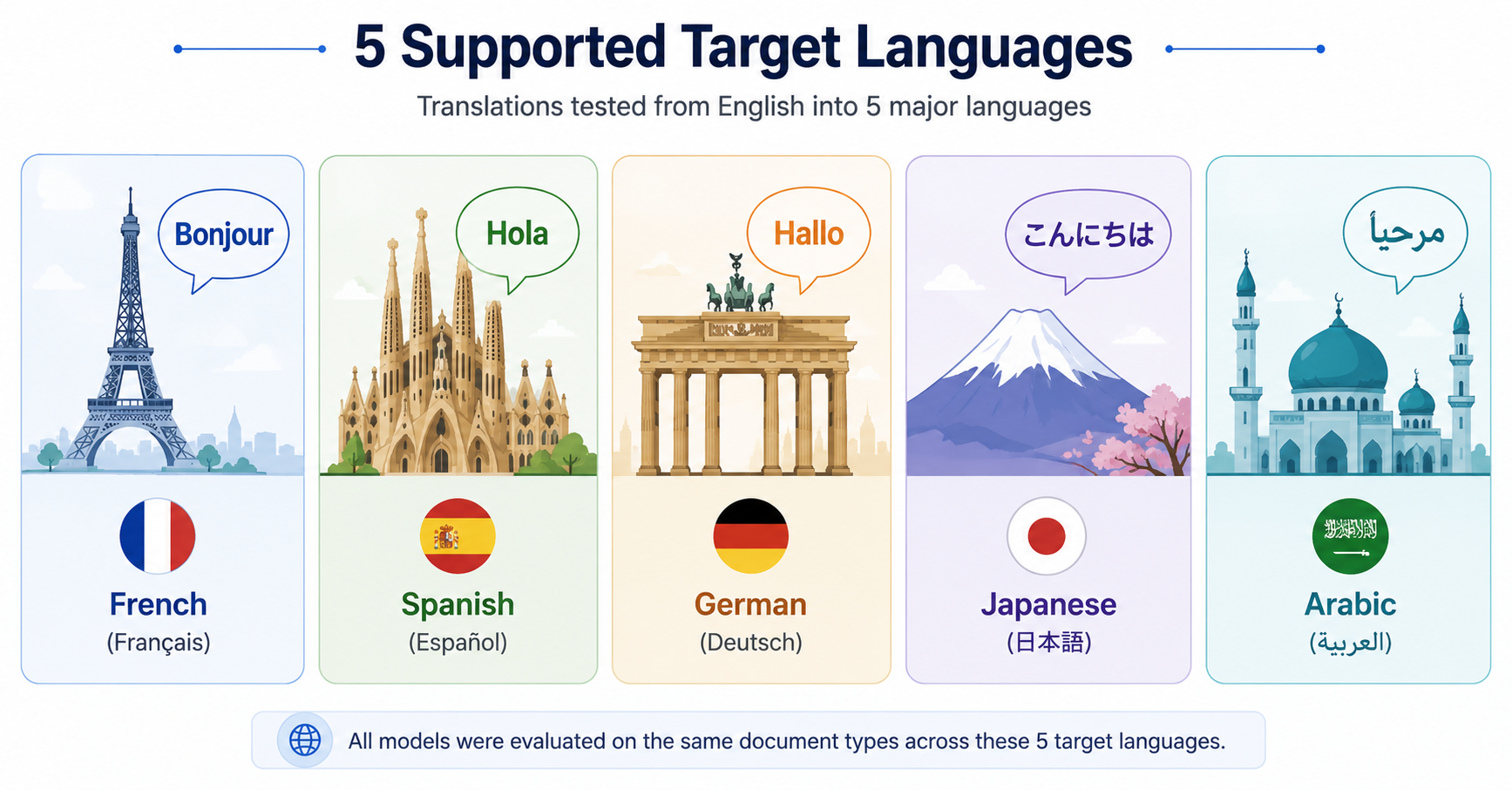
Each document was translated from English into:
-
French
-
Spanish
-
German
-
Japanese
-
Arabic
Evaluation Criteria
Two primary quality signals were evaluated:
1. Fluency
Whether the translated output reads naturally to a native speaker.
2. Fidelity
Whether the output preserves the exact meaning of the source text.
Special attention was given to:
-
negations
-
conditional clauses
-
legal phrasing
-
domain-specific terminology
-
culturally sensitive expressions
The 22 AI Translation Models Included
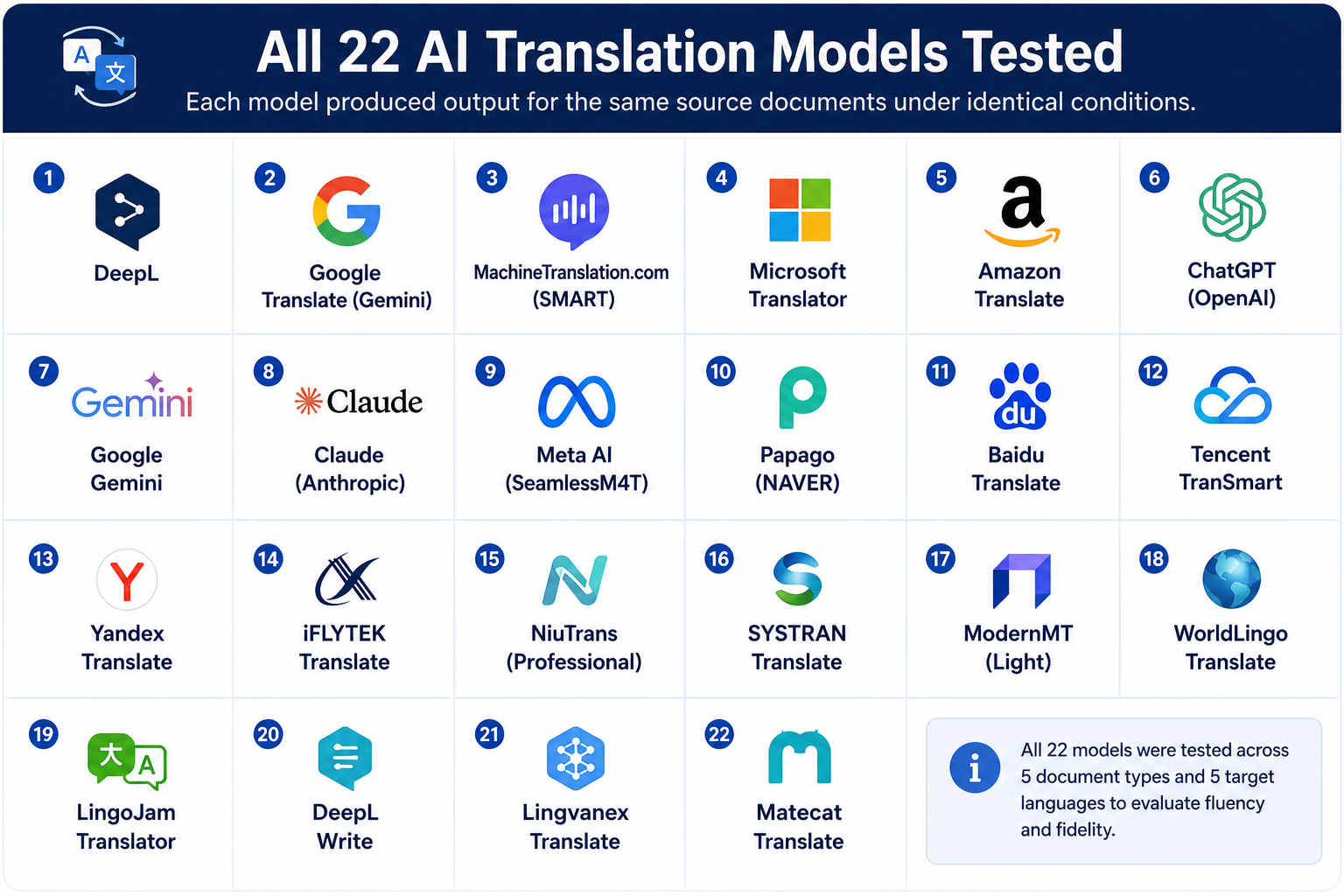
The comparison included outputs from leading machine translation engines and LLM-powered translation systems.
|
AI Translation Model |
Primary Strength |
|
MachineTranslation.com |
Multi-model comparison |
|
Google Translate |
General multilingual coverage |
|
DeepL |
Natural fluency |
|
Microsoft Translator |
Enterprise integration |
|
Gemini |
Context-aware translation |
|
Claude |
Long-context handling |
|
ChatGPT |
Conversational adaptation |
|
Amazon Translate |
Cloud workflow integration |
|
SYSTRAN |
Enterprise translation |
|
ModernMT |
Adaptive translation memory |
|
Lingvanex |
Multi-format support |
|
Reverso |
Contextual phrasing |
|
PROMT |
European language support |
|
Papago |
Asian language optimization |
|
Yandex Translate |
Broad language coverage |
|
Baidu Translate |
Chinese language support |
|
Naver Translate |
Korean language support |
|
IBM Watson Language Translator |
Enterprise AI workflows |
|
SDL Machine Translation |
Localization workflows |
|
KantanMT |
Custom domain adaptation |
|
Smartcat MT |
Translation management integration |
|
Language Weaver |
Large-scale localization |
What Consensus Reveals That Individual Scores Miss
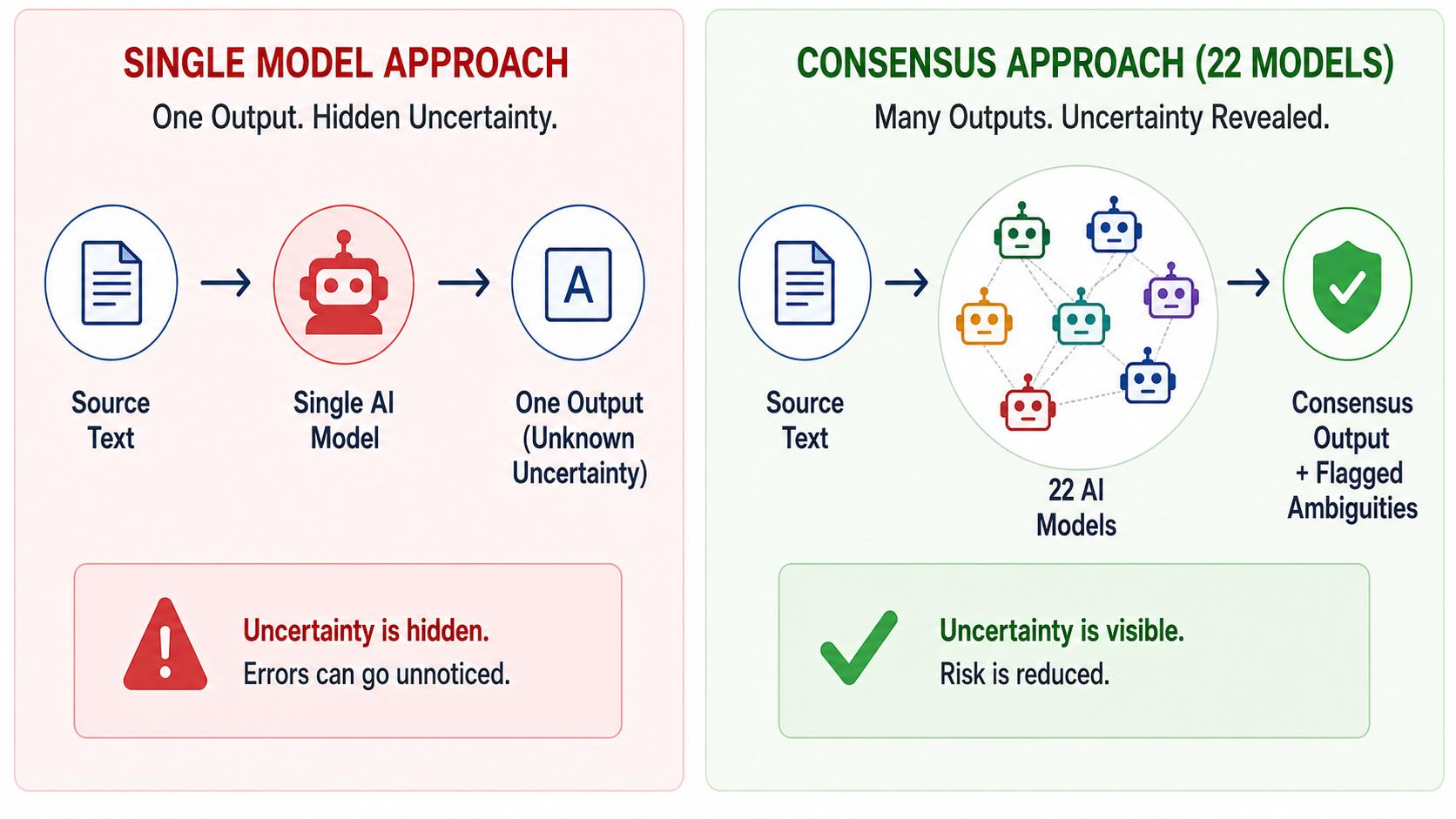
One of the clearest findings from the comparison was that disagreement between models often revealed difficult translation segments.
When multiple systems produced near-identical outputs, translations were usually reliable.
However, when outputs diverged heavily, the source text often contained:
-
ambiguous legal phrasing
-
culturally dependent language
-
idiomatic expressions
-
terminology conflicts
-
double negatives
This makes cross-model comparison useful not only for choosing a translation, but also for identifying where human review is most important.
Single-model systems rarely expose uncertainty directly.
They usually generate fluent outputs regardless of confidence level.
Consensus comparison introduces a visibility layer that standard translation workflows often lack.
How MachineTranslation.com Approaches This Problem
MachineTranslation.com, an Al translator, uses a multi-model translation workflow that compares outputs from multiple Al systems simultaneously.
Its SMART framework identifies translation segments where multiple models converge on similar outputs.
According to MachineTranslation.com's internal data, consensus-based comparison helps reduce outlier translations and improves visibility into uncertain segments.
Rather than relying entirely on a single engine, the workflow allows users to:
-
compare outputs side-by-side
-
identify translation disagreement
-
review alternative phrasing
-
evaluate ambiguity manually
This is especially useful for:
-
legal workflows
-
multilingual compliance
-
technical localization
-
enterprise documentation
-
customer-facing content
The platform aggregates outputs from multiple providers including Google Translate, DeepL, Gemini, Claude, and Microsoft Translator.
Key Findings From the Comparison
1. Fluency Is No Longer the Main Differentiator
Most top-tier AI translation systems now generate highly readable output for common language pairs.
The biggest differences appear in:
-
terminology consistency
-
ambiguity handling
-
specialized vocabulary
-
edge-case accuracy
2. Legal and Technical Content Still Require Human Review
Even advanced models occasionally:
-
softened legal negations
-
altered contractual intent
-
simplified technical terminology
-
omitted qualifiers
These errors were uncommon but high-impact.
3. Multi-Model Comparison Improves Risk Visibility
When multiple systems strongly disagreed, those segments frequently required manual review.
Consensus itself became a useful confidence signal.
4. Benchmark Scores Alone Are Insufficient
Aggregate benchmark accuracy does not always reflect performance on domain-specific content.
A model optimized for conversational fluency may still struggle with compliance-heavy documentation.
What This Means for Teams Evaluating AI Translation Tools
The AI translation market has grown to the point where 72% of translation agencies now integrate AI tools, up from 45% in 2020. But integration and reliable use are different things. The gap between a tool that produces fluent output and a tool that produces accurate output is invisible to anyone who evaluates AI translation by reading a few sample sentences.
For practical evaluation, three criteria matter more than aggregate accuracy scores:
Domain Consistency
Can the system maintain terminology and meaning across specialized content?
Transparency
Does the platform expose uncertainty and alternative outputs?
Review Efficiency
Can teams quickly identify which segments actually require human verification?
These criteria apply as much to AI translation as they do to any software category Fileion readers evaluate. The tools worth recommending are not always the ones with the best headline feature. They are the ones built around transparency about their own limitations. For a deeper look at AI-powered productivity tools in a similar vein, the Fileion overview of free AI-powered text tools applies the same evaluation logic to OCR and text processing workflows.
The Bottom Line
Twenty-two models tested across five document types and five language pairs produced one consistent finding: the models that perform best on fluency benchmarks are not always the models that perform best on fidelity for specialized content. And no model reliably flags its own uncertainty.
Consensus comparison does not eliminate that uncertainty. It makes it visible. For teams where a translation error carries real consequences, that visibility is the feature that matters most in 2026.



{kind=link}